ELI5: How does HTTP even work?
Arjun Aravind • 18 September 2020 • 10 min read If you're a regular internet user, then the term HTTP is definitely something that you would have come across. You might have needed to type in a URL or, if you're a developer, then you may have played around with REST APIs or something like that.
If you're a regular internet user, then the term HTTP is definitely something that you would have come across. You might have needed to type in a URL or, if you're a developer, then you may have played around with REST APIs or something like that.
Whatever the reason was, HTTP is one of those things that everyone uses regularly on a daily basis. It's one of the most important things that drives the world wide web as we know it!
It's also one of the most beautifully engineered things I've seen in my life.Learning how the world wide web, or the 'internet', works was an amazing experience for me as a developer. Just the fact that there are so many layers to it and that all of these layers work together so well is a real testament to human innovation.
Anyways, in this article, we will not be discussing all of these layers. In fact, we will only be talking about specific layer, HTTP. What it is, how it works and how it enables the internet to work so smoothly is what you will be reading about.
Let's get on with it then, shall we?
How does the internet work?
Now, before we talk about HTTP, I'd like to explain, very briefly, how webpages work. And, yup, don't worry, I'm going to make it as easy as possible *cracks knuckles*.
Webpages are essentially just a collection of HTML, CSS and Javascript files. For beginners; HTML, CSS and Javascript are programming languages that let you define how a webpage looks and behaves.
Browsers (such as Chrome, Firefox or Safari) are software that take all these files and, based on the code inside these files, display a webpage.
So, when you type in www.google.com in your browser and press 'enter', the browser gets all the related HTML, CSS and JS files and displays the webpage for you. This is the same for all websites. Even this one.
Now, you might have a question, where does the browser get these files from?
These files are stored in servers. Think of servers as computers which are switched on all the time and whose only job is to store webpage files and give them to browsers (sad life, right?). So, taking the earlier example, the browser would talk to the server storing www.google.com's files and get them.
However, there can be millions of servers around the world. How does the browser know which one contains www.google.com's files? The browser can figure this out by using the webpage's unique IP address.
We're almost done. One last step. To get the webpage's IP address, the browser needs to contact a special server called a 'DNS Server'. This contains a list of all websites and their IP addresses. Pretty convenient, right?
To make it easier, imagine it as a conversation between the browser and the servers! I've referred to the browser as a 'client' (it's the technical term).
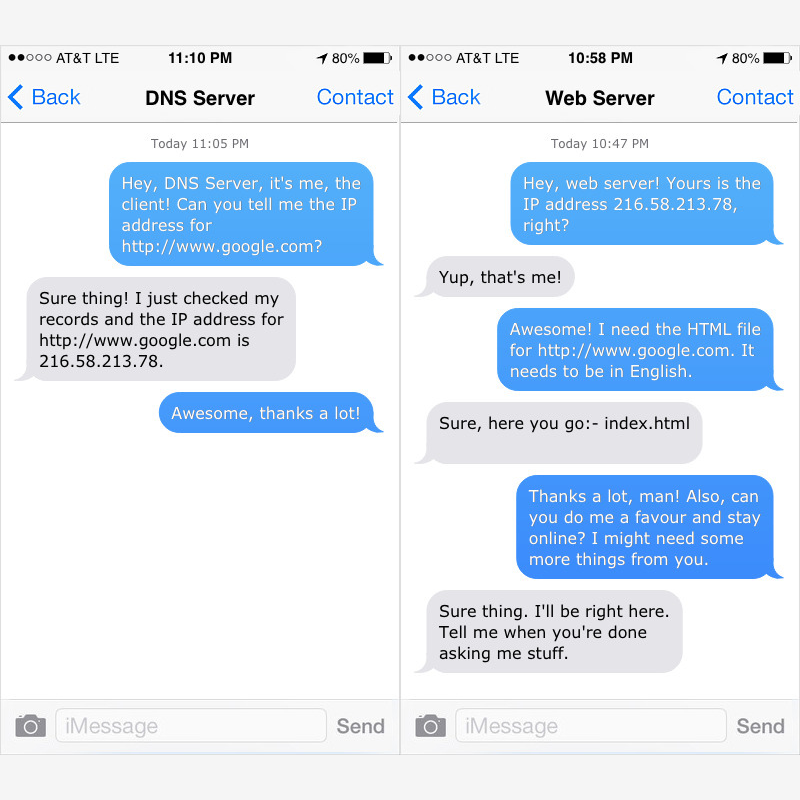
So that it's easier to understand, here's what a browser might have to go through!
That's it. That's literally it. I haven't gone into the details a lot but that's how the internet works!
One question remains, however. Servers could be present anywhere in the world. How are the files transported from them to our browsers?Okay, phew, time for a break! Let's take that in and come back in a few minutes.
Along with a lot of other layers, HTTP plays a major role in this.
How is HTTP useful?
Right, so as we mentioned in the last section, HTTP is what transports files from a server to a browser. By the way, from now on, I'll be referring to browsers as 'clients', I'll explain why later on.
HTTP stands for Hypertext Transfer Protocol.
What that means is that HTTP is a protocol (a set of instructions). These instructions define a format in which data or files can be transported from server to client.
Now, you might be confused, so don't worry, I will definitely explain this more and how it works but, before that, let's see why it's helpful.

Software developers might write browsers and servers in different languages. Some of these might even have different formats for sending and receiving data. Without agreeing on a common format, it would be a complete nightmare to send data and files from a server to a client.
But HTTP solves this! It provides a standard format with which we can describe the data being transported, where it must be transported and even how it must be transported.
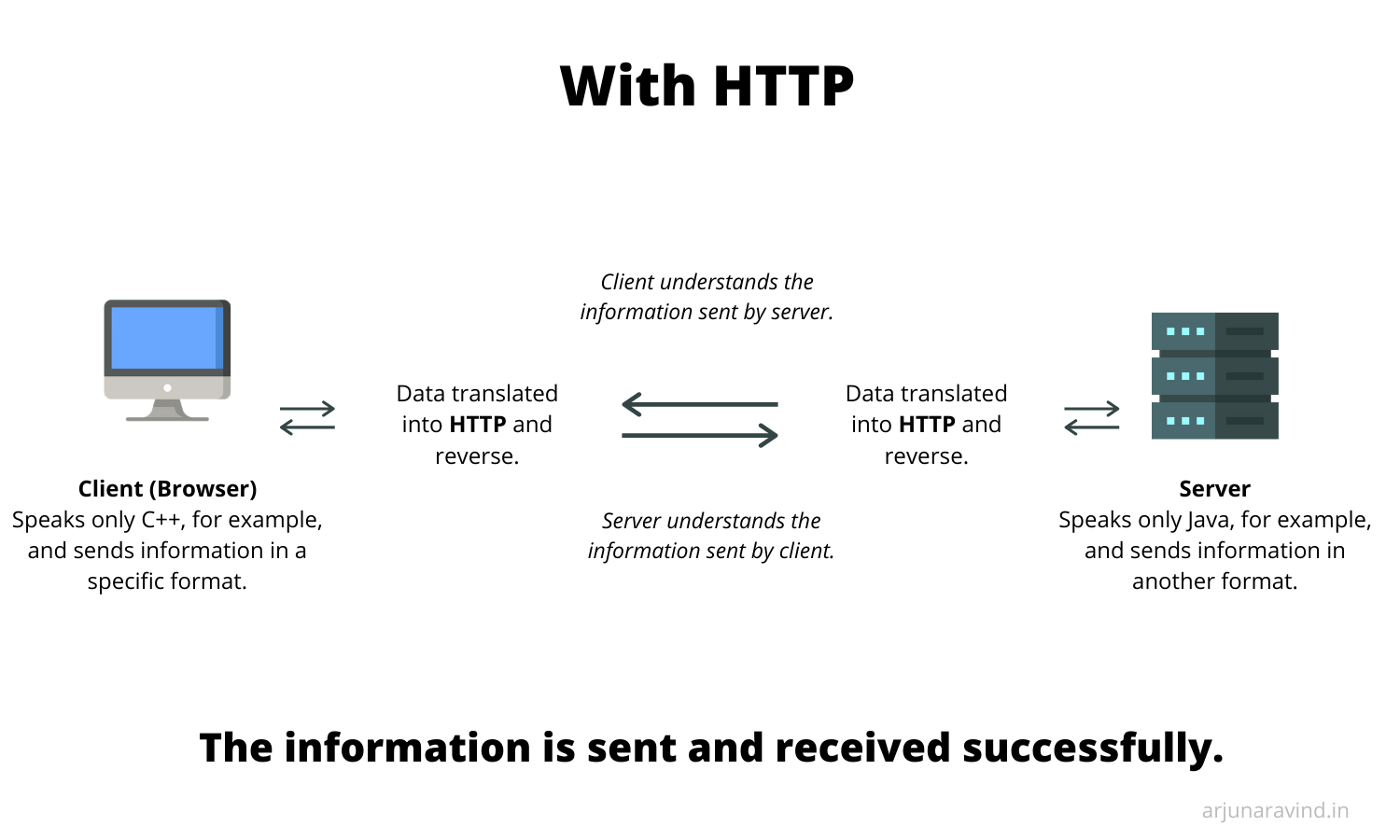
It's actually genius when you think about it. You can write web browsers and servers in any language you want and HTTP would take care of the heavy-lifting for you.
Who decides what the HTTP format must be?
The HTTP specification is decided by the IETF, the Internet Engineering Task Force (cool name). These are a group of people who volunteer to be a part of the deciding committee. They discuss about various additions and removals and then vote to make a decision.
Once the HTTP specifications have been defined, then browsers make sure they implement these specifications. So, for example, everytime something new is added to the HTTP specification, then the developers of browsers like Google Chrome or Safari must implement these additions in the browser.
Browsers which fully, and correctly, implement the HTTP specification are deemed 'HTTP-compliant' by the IETF. Examples are popular browsers like Edge, Chrome and Firefox.
But yes, there are browsers which might not properly implement the HTTP specification. If these are not deemed compliant by the IETF, then they might not be recommended for use.
One thing to note is that no one enforces all these rules and not being 'HTTP-compliant' might not ban your browser or something, but users might make a choice to not use it. The HTTP specification makes data transportation extremely smooth and not fully implementing it might affect the user experience for a browser.
Wow, so how does HTTP work anyways?
So, HTTP is basically a request-response cycle.
What I mean is that there is an entity which requests a particular resouce and there is another entity which responds with the requested resource if it has it.
Let's take an example. You want to view the google.com website. Your browser needs some resources (the HTML, CSS and JS files, in this case) from the server and, so, it sends a 'HTTP request'. The server sends back a 'HTTP response' which contains the file necessary.
One thing to remember would be that there needs to be a seperate request and response for every single resource or file.
A typical HTTP request would look like this.
GET /index.html HTTP/1.1
Host: www.google.comI think it's pretty self-explanatory, right? We want to 'get' the HTML file called
index.htmlwww.google.comThe server will respond with a HTTP response which typically looks like this.
HTTP/1.1 200 OK
Date: Fri, 19 Dec 2020 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 155
Last-Modified: Wed, 10 Jan 2020 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>Google</title>
</head>
<body>
<p>Welcome to google.com!</p>
</body>
</html>This is pretty simple to understand as well. Let's start from the first line.
In line 1, the HTTP response first specifies the HTTP version number which, in this case, is
1.1200 OK- There are various HTTP status codes. You might have heard about the popular '404 Not Found' message which is usually returned when the server cannot find the specified resource!
- The '200 OK' is returned if the resource exists in the server and is sent successfully.
- In case you're interested to see a complete list of status codes and messages, check this page out!
In lines 2-8, the response contains what are known as HTTP headers. Headers provide useful and necessary information about the data being sent such as when it was created, last modified, its size, etc.
- There are hundreds of HTTP headers and some of them are really interesting!
- Examples would be 'Content-Type' (the type of data being sent), 'Referer' (the website from which you came to this link) and 'Cache-Control' (whether the browser can cache the file or not).
- For a complete list of headers, read this wikipedia article!
Lines 10-17 are the data being sent. This is the
index.html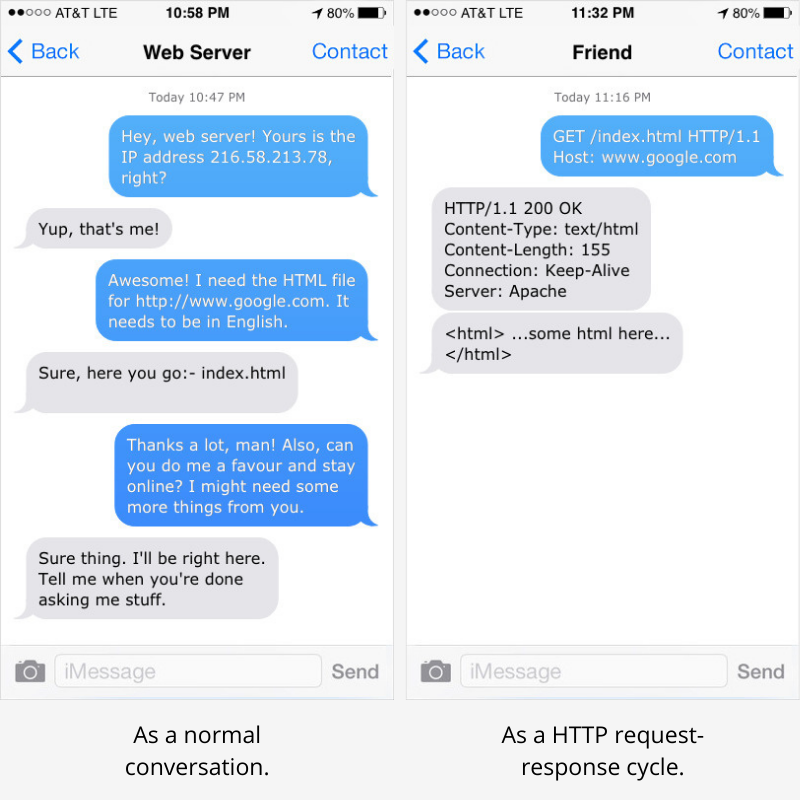
The example from the second section could also be represented like this.
Similarly, every single file on a webpage requires a request and then a response.Shown below are the HTTP responses that my browser gets when it goes to www.arjunaravind.in. You can see that there are multiple responses due to multiple files being requested!
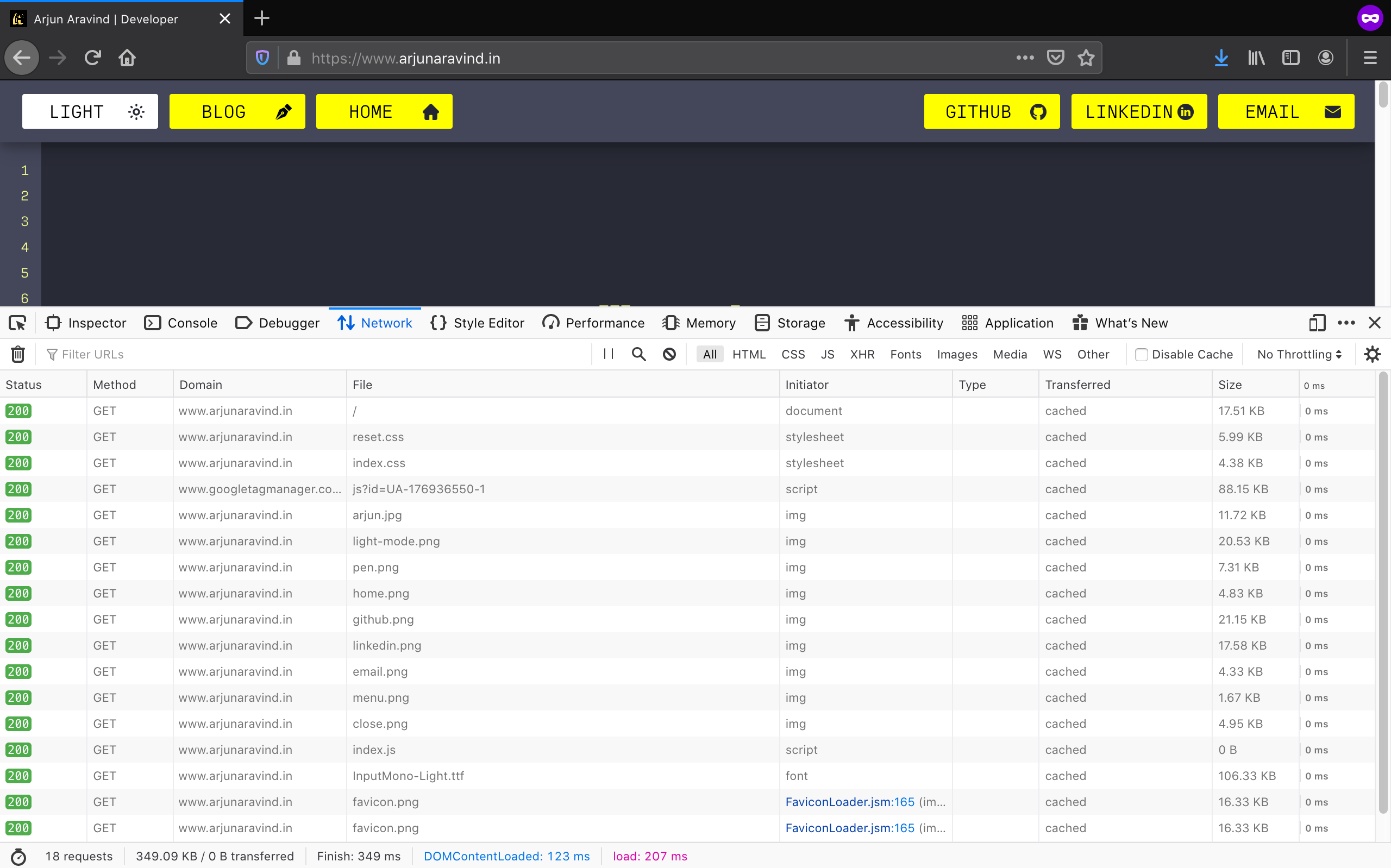
You can view these HTTP requests and responses in your browser too! Simply go to any website, right-click in the browser and click 'Inspect'. You should see a panel appearing with a lot of tabs. There will be a tab named 'Network'. Click on that and you should see all the activity happening behind-the-scenes!
One thing to note is that the browser doesn't show us the 'raw' HTTP message here. It beautifies the requests and responses to make it easier for us to read.
---------------
Well, that's it for today! There are a few more topics I would have liked to cover but I wouldn't want to overwhelm you. This article was also getting pretty long. But I do intend to cover those in detail in seperate articles.
If there are any corrections or mistakes or if you just wanna talk, hit me up. I hope this helped and stay tuned!